
Building a Neighborhood Change Database
In this project we are ultimately interested in building models to explain neighborhood change between 1990 and 2010.
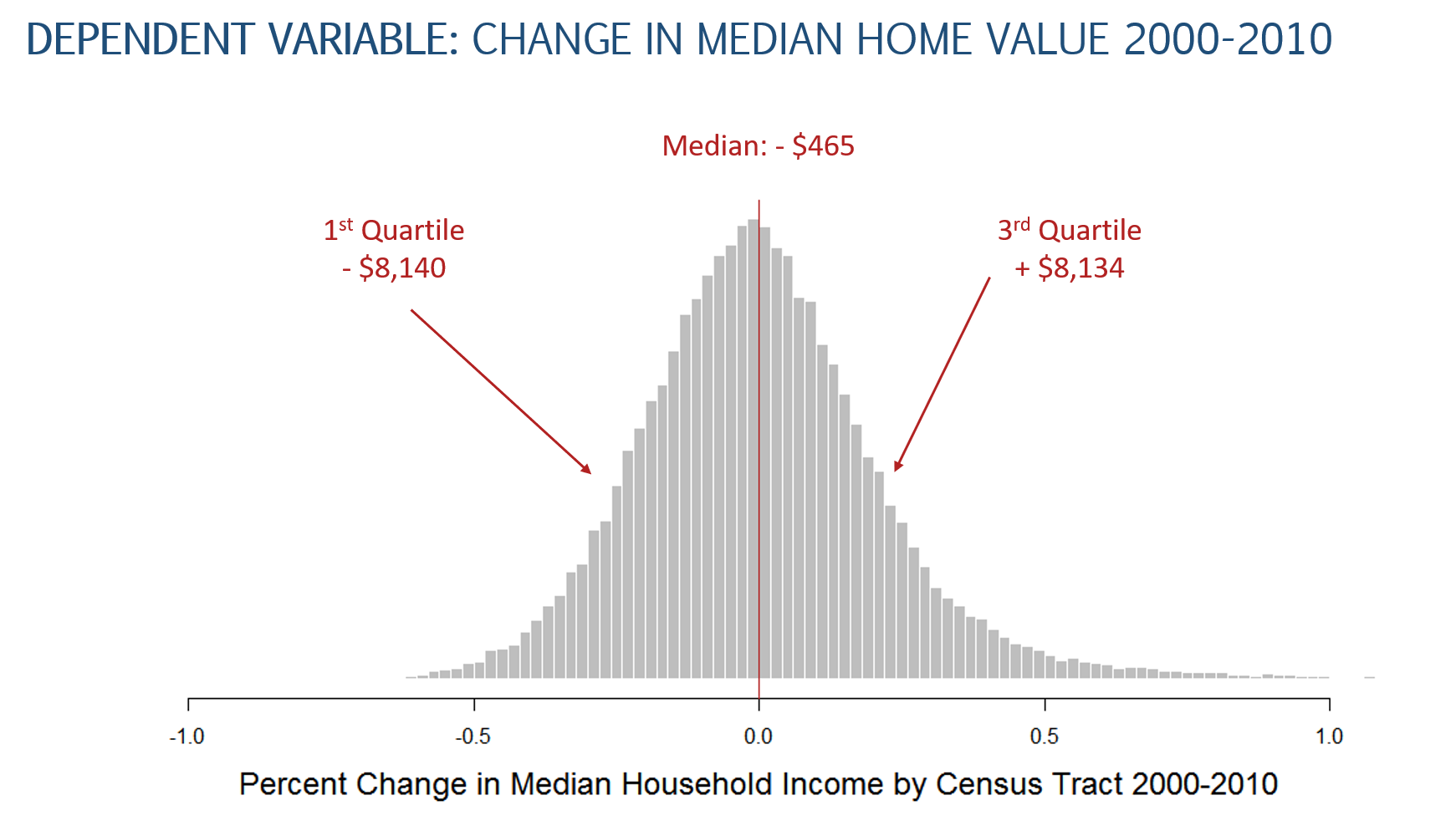
Census data is central to this analysis. We have begun using the harmonized Longitudinal Tracts Data Base, and by now you understand the challenges of working with the data.
This unit covers the remaining data steps necessary to wrangle the harmonized census data into a meaningful format necessary to conduct descriptive analysis.
Background Material
CRISP-DM is a useful checklists used for planning data-driven projects.
Cross-industry standard process for data mining (CRISP-DM) describes six major iterative phases, each with their own defined tasks and set of deliverables such as documentation and reports.
- Business Understanding: determine business objectives; assess situation; determine data mining goals; produce project plan
- Data Understanding: collect initial data; describe data; explore data; verify data quality
- Data Preparation (generally, the most time-consuming phase): select data; clean data; construct data; integrate data; format data
- Modeling: select modeling technique; generate test design; build model; assess model
- Evaluation: evaluate results; review process; determine next steps
- Deployment: plan deployment; plan monitoring and maintenance; produce final report; review project
Each step in the model is designed to help a team anticipate tasks in the data analytics process.
This phase of the class project focuses on the following task lists in CRISP-DM:
Data Understanding
The second stage consists of collecting and exploring the input dataset. The set goal might be unsolvable using the input data, you might need to use public datasets, or even create a specific one for the set goal.
- Collect Initial Data
- Initial Data Collection Report
- Describe Data
- Data Description Report
- Explore Data
- Data Exploration Report
- Verify Data Quality
- Data Quality Report
Data Preparation
As we all know, bad input inevitably leads to bad output. Therefore no matter what you do in modeling — if you made major mistakes while preparing the data — you will end up returning to this stage and doing it over again.
- Select Data
- The rationale for Inclusion/Exclusion
- Clean Data
- Data Cleaning Report
- Construct Data
- Derived Attributes
- Generated Records
- Integrate Data
- Merged Data
- Format Data
- Reformatted Data
- Dataset Description
Reference Material:
Jenny Bryan has a great presentation on the power of naming conventions for files: Naming Things.
Note that the name uses the phrase “for data mining”, but it is a general framework for data science projects that was developed when “data mining” was a popular term used to describe an emerging field. In the metaphor the data is the rich medium that analysts mine for insights about business processes. The term has fallen out of favor because mining sounds atheoretical. Computer scientists were criticized for developing algorithms that can detect patterns and make predictions without any understanding of the processes or contexts, often leading to ethically questionable recommendations or problematic recommendations. The phrase “data science” was adopted to convey that there is a method to the madness. The CRISP-DM process applies broadly to most data science projects.
For a slightly more extensive list of tasks at each phase, see:
Examples of Integration of the CRISP-DM Process in R
CRISP-DM is one example of a project task-list, but not the only option. You will find that the R community has started incorporating some of these process models / project management tools into R packages:
Portability & Version Control
Fundamentally, portability and version control are all about making sure that other people are:
- able to re-run your code; and
- establish a clear history of edits that make it possible to identify, communicate, and ultimately resolve bugs in your code.
These concepts will be enforced through four tools:
- RStudio Projects;
- The renv package;
- The .gitignore file; and
- Version control techniques via GitHub.
Slide deck & transcript
This week will be the most demanding in terms of learning and directly applying what is covered in this week’s videos. To break up the videos into digestable pieces of content, each tool is covered in two types of videos: lectures & tutorials.
All content covered in each of these videos is documented in this Presentation. All transcripts from each lecture are preserved in the Document.
The videos are presented in the order that they should be watched:
Intro to WK02 Concepts
Intro to Portability & RStudio Projects
Lecture:
Tutorial:
renv package
Lecture:
Tutorial:
.gitignore file
Lecture:
Tutorial:
Git Feature Branch Workflow
Lecture:
Tutorial:
Import Functions and Build Variable Filters
Tutorial:
Resources mentioned in video:
- Github Desktop
- Git
- R Function Returns
- Grepl and regex packages
- Regular Expression in R
- Regex tutorial
- Regex Cheatsheet #1
- Regex Cheatsheet #2